I am a visual computing researcher—computer vision, computer graphics, and human-computer interaction. My lab develops techniques for image and video creation, editing, analysis, and interaction. This requires image and scene reconstruction techniques, especially from multi-camera systems and for complex dynamic scenes, and with applications on 2D, multi-view, and VR/AR displays.
Practical Scene & Object Reconstruction
How do we reconstruct scenes and objects from photographs, especially for unstructured capture, complex appearance, and large places?
In my lab and with our great collaborators, we reconstruct scenes and objects from images. Each project fits a representation of 3D shape and appearance so that the model's rendered images match the captured ones. With many images in controlled conditions, this problem is solvable; what makes it interesting is when we work with few casual captures, or with challenging appearance, or in large and uncontrolled conditions. These cases often contain visual ambiguities and rarely have a single solution.
We've tried to tackle this space of problems: with large scenes both indoors and out; with handheld, 360, or airborne cameras, with sparse and wide baselines; with surfaces that interreflect, refract, and are lit by many sources. Across the projects, the contribution often focuses on what specific information can reduce the ambiguity: a physically based rendering model that better matches real light and cameras, or a scene representation matched to the scene's own structure. This idea applies from a single object up to a building or street scene, from a phone to a drone, and from synthesising new views of a scene to measuring its properties.
Authors
Hujun Bao · Dongyoung Choi · Yaoan Gao · Purvi Goel · Qixing Huang · Hakyeong Kim · Min H. Kim · Yifan Peng · Belal Shaheen · Yujun Shen · Vikas Thamizharasan · Huamin Wang · Xiuchao Wu · Jiamin Xu · Weiwei Xu
Papers in this thread
Related papers
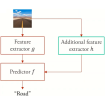
Monocular Dynamic 3D Reconstruction
With only ordinary RGB video—no depth sensor, no rig—can we recover dynamic 3D scene geometry and motion?
Monocular dynamic 3D reconstruction takes a single moving camera observing a deforming scene and tries to recover a 4D representation including geometry, appearance, and motion. The problem is fundamentally under-constrained at any one instant, and progress depends on how well the chosen scene representation and supervision signals work together.
We've approached this in two ways. First, per-scene methods fit a representation to a single video. We consider what motion models and regularisations can help (GauFRe, MonoDyGauBench), and what additional information might resolve the ambiguity, e.g., semantics, attention, and optical flow supervision (SAFF). Second, Zero-MSF is data driven: a feed-forward model trained on millions of synthetic examples that transfers zero-shot to real video, with no per-scene fitting.
Authors
Orazio Gallo · Leonidas J. Guibas · Adam Harley · Numair Khan · Eliot Laidlaw · Douglas Lanman · Yiqing Liang · Runfeng Li · Mikhail Okunev · Lei Xiao
Papers in this thread
Active Illumination for Dynamic 3D Reconstruction
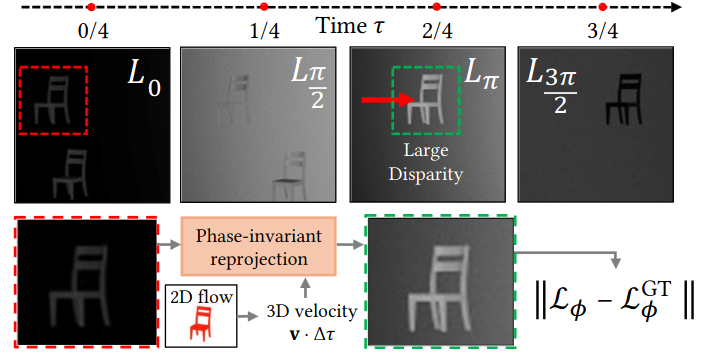
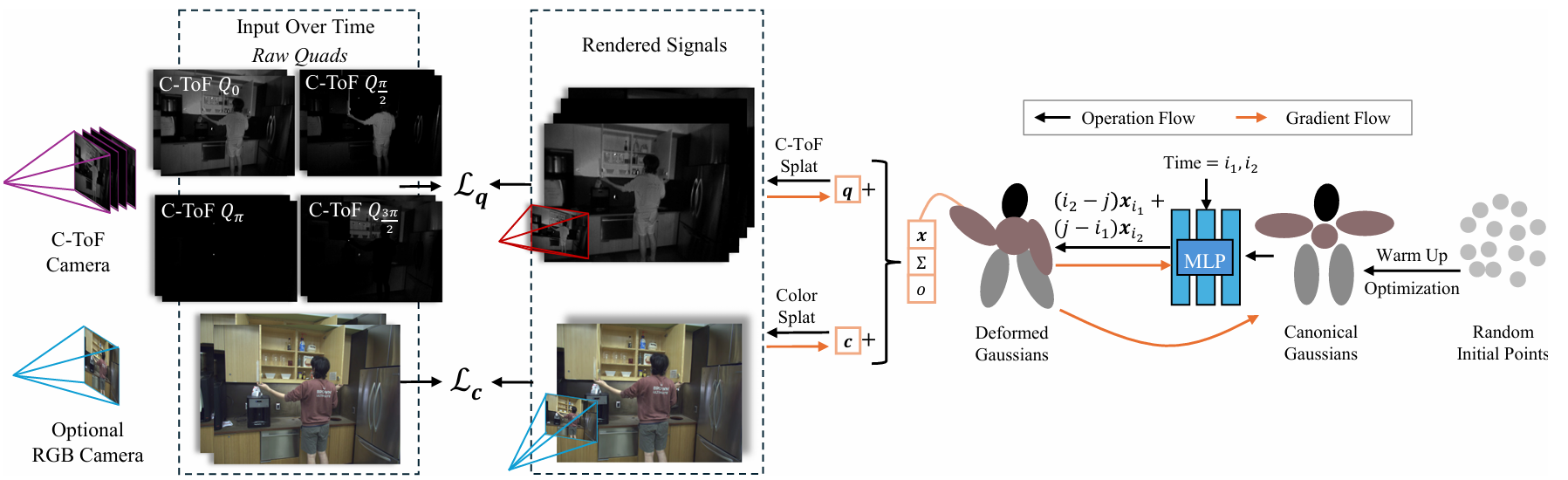
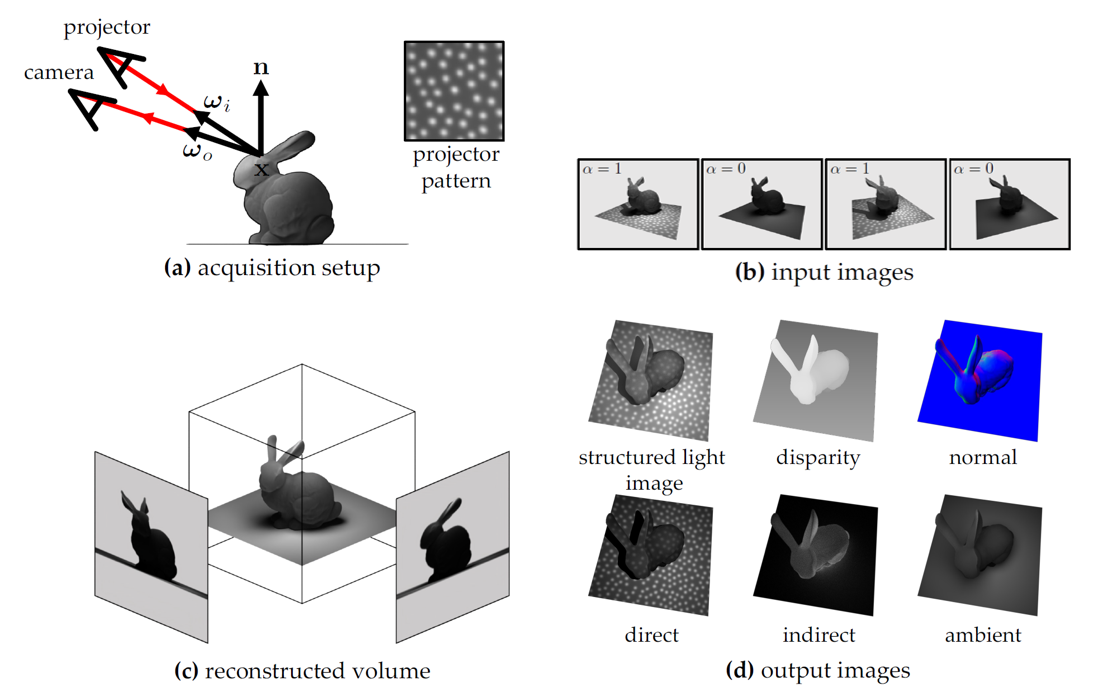
Can physically modelling active illumination directly from raw sensor measurements improve scene estimation and avoid errors from derived depth?
Time-of-flight and structured-light cameras are typically used as depth sensors: their raw measurements are processed into a per-pixel depth map, and downstream reconstruction methods treat that depth as input. But depth processing makes simplifying assumptions about the scene, creating noise in low-reflectance regions, flying pixels under multi-path interference, and motion artifacts in fast-moving scenes—each depth estimate needs multiple illumination readings. Further, derived depth is difficult to integrate with other sensor modalities, like colour cameras.
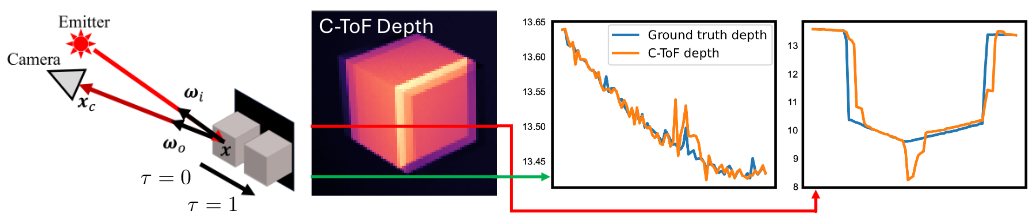
Our work rethinks reconstruction for heterogeneous multi-shot imaging processes. Built upon a differentiable forward model of how the active illumination produces the raw sensor output for a given scene, our methods optimise a 4D volumetric scene representation (like NeRF or 3DGS) so that rendered measurements match what the sensor captured. This lets us integrate sensor measurements over spacetime in a principled way, including across modalities, to reduce noise, resolve ambiguities in multi-shot sensing, and improve robustness to multi-path interference. And since we model motion over time, we can resample fast motion—a swinging baseball bat—into slow motion.
Authors
Benjamin Attal · Aaron Gokaslan · Changil Kim · Hakyeong Kim · Eliot Laidlaw · Runfeng Li · Marc Mapeke · Andreas Meuleman · Matthew O'Toole · Mikhail Okunev · Christian Richardt · Aarrushi Shandilya
Papers in this thread

Related papers

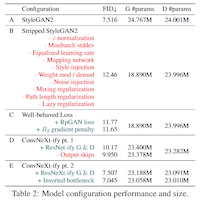
Controllable Generative Models
How do we efficiently control generative models to produce what we want—preserving identity, 3D structure, style—without sacrificing quality?
A generative model that can sample new content is impressive; one that produces exactly what a user has in mind is useful. Controlling generation requires aligning the model's latent structure with axes a person can articulate—identity, pose, style, lighting, geometry—without sacrificing the photorealism that brought the model to relevance in the first place. There is usually a quality-versus-control tradeoff to manage.
This thread runs from Youssef Mejjati's PhD work on unsupervised attention for image-to-image translation, through compositional controls (object stamps, GaussiGAN's 3D Gaussian primitives from silhouettes alone), into 3DMM-conditioned face generation where Yiwen Huang's PhD now sits. Two recent moves matter: TaxFreeGAN closes the FID gap to unconditional StyleGAN under 3DMM conditioning, and our disentangling-3D work shows that the noise in CLIP's embedding space—not the disentanglement strategy—is what kills quality. R3GAN sits alongside this arc as our architectural reset: a principled relativistic loss that lets the modern GAN drop its bag of tricks.
Authors
Aaron Gokaslan · Yiwen Huang · Hyeongwoo Kim · Kwang In Kim · Atsunobu Kotani · Volodymyr Kuleshov · Youssef A. Mejjati · Isa Milefchik · Zejiang Shen · Michael Snower · Stefanie Tellex · Vikas Thamizharasan · Oliver Wang · Xinjie Yi · Zhiqiu Yu · Qian Zhang
Papers in this thread


Light Fields—from Display to 4D Algorithms
The light field is a 4D record of a scene's rays—how do we present it to humans, interact with it, and process it computationally?
A light field captures the radiance at every point in space, in every direction—a 4D function that fully describes how light fills a scene. Captured light fields enable refocusing, depth recovery, and parallax view synthesis; displayed light fields offer glasses-free 3D. The challenge is data density: 4D content stresses capture devices, display hardware, and processing pipelines.
Two sub-arcs sit in this thread. In the first (2012–2015), I targeted light field displays—an Emerging Technologies demo of painting directly into a glasses-free 3D display, content-adaptive lenticular prints that reshape the lenslet array to the captured light field, and a UIST paper that turns that lenslet array into a joint display-and-pen-input surface. In the second (2019–2021), Numair Khan and I, with Min H. Kim at KAIST, developed algorithms for dense estimation over captured 4D content: view-consistent superpixels via epipolar-plane image segmentation, edge-aware bidirectional diffusion for depth, and a differentiable diffusion routine for sparse-to-dense depth from multi-view images.
Authors
Marc Alexa · Lucas Kasser · Jan Kautz · Numair Khan · Min H. Kim · Wojciech Matusik · James McCann · Samuel Muff · Hanspeter Pfister · Henry Stone · Qian Zhang
Papers in this thread

Editing Video by Recovering Scene Structure
How can we edit captured video? By recovering the scene structure (geometry, dynamics, lighting, reflectance, cross-frame consistency) that makes plausible modifications possible.
Editing video is harder than editing a photograph: changes to one frame must propagate consistently to every other, and many edits (removing a person, separating lighting from material, stabilising flicker) require understanding the underlying scene rather than just manipulating pixels. We approach editing as inverse reconstruction: decompose video into scene structure first, then edit.
This thread spans my doctoral and postdoc years across UCL, MPI-Inf, Harvard, and LIRIS-CNRS. My earliest piece (2011, UCL) is the cinemagraphs authoring tool—a moment image isolated from a stabilised clip. Miguel Granados led the video-inpainting work at MPI-Inf (2012)—removing dynamic objects from crowded scenes, and the harder case of background recovery under a free-moving camera. Nicolas Bonneel led the consistency and decomposition line (2014–2017)—interactive intrinsic decomposition, blind temporal consistency stabilising any per-frame filter, and the spatio-temporal extension to camera arrays. Our 2016 multicut paper takes a different angle on the same theme: cut the video into the right regions before editing.
Authors
Nicolas Bonneel · Miguel Granados · Jan Kautz · Kwang In Kim · Evgeny Levinkov · Sylvain Paris · Hanspeter Pfister · Kartic Subr · Kalyan Sunkavalli · Deqing Sun · Christian Theobalt · Oliver Wang
Papers in this thread
|
European Conference on Computer Vision (ECCV), 2026
|
|
|
MotionSplicer: Part-Based Motion Editing for 4D Volumetric Videos
European Conference on Computer Vision (ECCV), 2026
|
|

|
European Conference on Computer Vision (ECCV), 2026
|
|
International Conference on 3D Vision (3DV), 2026
|
|

|
MDPI Remote Sensing, 2026
|
|
SIGGRAPH Asia Conference Papers, 2025
|
|

|
2025
|
|
Computer Vision and Pattern Recognition (CVPR), 2025
|
|
|
Computer Vision and Pattern Recognition (CVPR), 2025
|
|
|
SIGGRAPH Asia Conference Papers, 2024
|
|
|
|
Neural Information Processing Systems (NeurIPS), 2024
Thread: Controllable Generative Models
|
|
Transactions on Machine Learning Research (TMLR), 2025
|
|
European Conference on Computer Vision (ECCV), 2024
|
|

|
Transactions on Visualization and Computer Graphics (IEEE Visualization Short Paper), 2024
|

|
Computer Vision and Pattern Recognition (CVPR), 2024
|

|
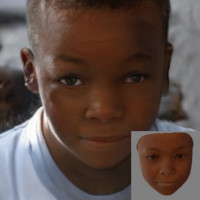
2025
Gives insight into why disentangling with CLIP is difficult—it's the prompt noise!
Thread: Controllable Generative Models
|
|
Winter Conference on Applications of Computer Vision (WACV) + AI for Content Creation (AI4CC) @ CVPR, 2024
Thread: Controllable Generative Models
|
|
arXiv (Dec. 2023) + WACV, 2025
|
|
Transactions on Graphics (SIGGRAPH Asia), 2023
|
|
|
International Conference on Computer Vision (ICCV), 2023
|
|

|
International Conference on Computer Vision (ICCV), 2023
|

|
International Journal of Computer Vision (IJCV), 2024
|

|
Transactions on Applied Perception (TAP), 2023
|

|
Conference on Human Factors in Computing Systems (CHI), 2023
|

|
Learning Vector Quantized Shape Code for Amodal Blastomere Instance Segmentation
International Symposium on Biomedical Imaging (ISBI), 2023
|
|
Transactions on Graphics (SIGGRAPH), 2022
|
|
|
Eurographics State of the Art Report + CVPR Tutorial + SIGGRAPH Course, 2022
|

|
European Conference on Computer Vision (ECCV), 2022
|

|
International Conference on Computational Photography (ICCP), 2022
|

|
Conference on Human Factors in Computing Systems (CHI), 2022
|

|
Computers & Graphics, 2022
For recovering depth, this follows up Blind Video Spatio-Temporal Consistency and Blind Video Temporal Consistency.
|

|
International Conference on Computational Visual Media (CVM), 2022
Also appeared at AI for Content Creation (AI4CC) @ CVPR 2021.
Thread: Controllable Generative Models
|

|
Transactions on Visualization and Computer Graphics (TVCG), 2022
Hosted at the Open Science Foundation.
|
|
Neural Information Processing Systems (NeurIPS), 2021
|
|
|
International Conference on Computer Vision (ICCV), 2021
|
|
|
Computer Vision and Pattern Recognition (CVPR), 2021
|

|
British Machine Vision Conference (BMVC) + AI for Content Creation (AI4CC) @ CVPR, 2021
Thread: Controllable Generative Models
|

|
Transactions on Visualization and Computer Graphics (TVCG), 2021
|
|
European Conference on Computer Vision (ECCV), 2020
|

|
European Conference on Computer Vision (ECCV), 2020
Thread: Controllable Generative Models
|
|
British Machine Vision Conference (BMVC), 2021
|
|
|
British Machine Vision Conference (BMVC), 2020
|
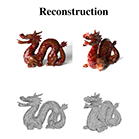
|
International Conference on 3D Vision (3DV), 2020
|
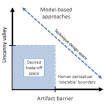
|
Real VR – Immersive Digital Reality, 2020
Chapter in the Real VR – Immersive Digital Reality Springer book; DOI.
|
|
Transactions on Visualization and Computer Graphics (IEEE Visualization), 2020
|
|

|
Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2020
|
|
|
International Conference on Computer Vision (ICCV), 2019
This work also produces an occlusion-aware piecewise planar scene reconstruction as a byproduct!
|

|
User Interface Software and Technology (UIST), 2019
|

|
International Conference on Virtual-Reality Continuum and its Applications in Industry (VRCAI), 2019
|
|
Conference on Human Factors in Computing Systems (CHI), 2019
|
|
|
Transactions on Visualization and Computer Graphics (IEEE Visualization Short Paper), 2019
One-line SVG pan/zoom, plus a pan/zoom injecting bookmark for any SVG! The project page hosts docs, jsFiddle, and bl.ocks.org examples.
|
|

|
International Journal of Robotics Research (IJRR), 2019
|
|
|
Neural Information Processing Systems (NeurIPS), 2018
Thread: Controllable Generative Models
|

|
European Conference on Computer Vision (ECCV), 2018
|

|
Transactions on Visualization and Computer Graphics (IEEE Visualization), 2018
Project page bundles the paper, code, and data.
|
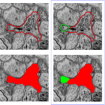
|
Computer Vision and Pattern Recognition (CVPR), 2018
|

|
Computer Vision and Pattern Recognition (CVPR), 2018
|

|
Symposium on Eye Tracking Research and Applications (ETRA), 2018
Project page bundles paper and code; dataset is hosted separately.
|

|
British Machine Vision Conference (BMVC), 2017
|

|
Computer Graphics Forum (Eurographics), 2017
We could have called it Blind Video Spatio-Temporal Consistency as it follows up Blind Video Temporal Consistency.
|

|
International Conference on Computer Vision (ICCV), 2017
|

|
Conference on Human-Robot Interaction (HRI), 2017
|
|
|
International Symposium on Robotics Research (ISRR), 2017
|

|
MDPI Informatics—Special Issue on Scalable Interactive Visualization, 2017
|
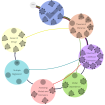
|
Transactions on Visualization and Computer Graphics (IEEE Visualization), 2016
|

|
Pacific Graphics (Short Paper), 2016
|
|
|
User Interface Software and Technology (UIST), 2015
Also at SIGGRAPH Emerging Technologies 2012: Interactive Light Field Painting
|

|
Transactions on Graphics (SIGGRAPH Asia), 2015
Builds upon project: Direct Motion Mapping
|

|
Transactions on Graphics (SIGGRAPH Asia), 2015
Related project: Blind Video Spatio-Temporal Consistency
|

|
Transactions on Graphics (SIGGRAPH Asia), 2015
|

|
Symposium on Computer Animation (SCA), 2015
|
|
Computer Vision and Pattern Recognition (CVPR), 2015
|

|
International Conference on Computer Vision (ICCV), 2015
|

|
Computer Vision and Pattern Recognition (CVPR), 2015
|

|
Transactions on Graphics (SIGGRAPH Asia), 2014
|
|
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2014
|
|

|
European Conference on Visual Media Production (CVMP), 2014
Related project: Vidicontexts
|

|
Computer Graphics Forum (Eurographics), 2014
Related project: Generalized Wave Gestures
|

|
Transactions on Graphics (SIGGRAPH Asia), 2013
|
|
International Conference on Computer Vision (ICCV), 2013
|

|
User Interface Software and Technology (UIST), 2013
Related study into display device effect: Device Effect on Panoramic Video+Context Tasks
|

|
Transactions on Applied Perception (TAP), 2013
|

|
Transactions on Graphics (SIGGRAPH), 2013
Printing light field displays with varying spatio-angular resolution.
|
|
|
EngD Thesis @ University College London, 2013
Also archived at UCL Discovery. Related projects: Videoscapes, Transition Analysis, Match Graph Construction.
|

|
European Conference on Visual Media Production (CVMP), 2012
Alt title: Light Field Video Textures
|

|
European Conference on Computer Vision (ECCV), 2012
Project page includes the dataset.
|

|
European Conference on Computer Vision (ECCV), 2012
Useful for building correspondence graphs for image matching, e.g., in search or large-scale reconstruction. Supplemental material.
|

|
Transactions on Graphics (SIGGRAPH), 2012
|

|
SIGGRAPH Emerging Technologies, 2012
Early demo of our later UIST 2015 publication Joint 5D Pen Input for Light Field Displays. Demo project page also at MIT CDFG.
|

|
Computer Graphics Forum (Eurographics), 2012
Project page includes the dataset.
|

|
Computer Graphics Forum (Eurographics), 2012
Project page includes code and data.
|

|
Transactions on Graphics (SIGGRAPH), 2011
|
|
|
European Conference on Visual Media Production (CVMP), 2011
|

|
International Brain-Computer Interface Conference (BCI), 2011
|

|
Conference on Human Factors in Computing Systems (CHI), 2010
|

|
British HCI Group Annual Conference on People and Computers (BCS-HCI), 2009
Webpage contains many projects and events! Schematics and WebGL model viewer!
|
|
MSci Dissertation @ King's College London, 2006
|
Workshops and Courses
AI for Content Creation
CVPR 2019–2026 Workshop
Physics-inspired 3D Vision and Imaging
CVPR 2025 Workshop
Neural Fields Beyond Conventional Cameras
ECCV 2024 Workshop
Neural Fields in Visual Computing
CVPR 2022 Tutorial + SIGGRAPH 2023 Course
New England Computer Vision Symposium
Brown 2019
Video for Virtual Reality
SIGGRAPH 2017 Course
User-centric Computational Videography
SIGGRAPH 2015 Course
University Courses
CSCI 1430—Introduction to Computer Vision
Brown University
2016–now.
CSCI 1290—Computational Photography
Brown University
2018–now.
CSCI 2951-I—Computer Vision for Graphics and Interaction
Brown University
2016–now.
CSCI 2000—Computer Science Research Methods or How to be a CS PhD Student
Brown University
2021 Fall.
CSCI 1950-N—2D Game Engines
Brown University
2017–now. Mentoring student-led course.
GISP 0002—NFTs, Blockchain, and Art, led by Ally Zhu and Nikolas Lazar
Brown University
2022 Spring.
CS171—Visualization
Harvard University
2016 Spring, 2015 Spring.
Computer Vision for Computer Graphics
Max-Planck-Institute for Informatics
2013 Summer.
Doctoral Students
Masters Students
Undergraduate Students
|
2023–2024
|
|
2022–2024
On to: General Dynamics
|
|
2021–2023
On to: CMU Research Masters; UW PhD
|
|
2022–2023
On to: Harvard Data Science Masters
|
|
2021–2023
On to: Harvard Computational Science and Engineering Masters
|
|
2020–2022
On to: Common Sense Machines
|
|
2017–2020
On to: UC Berkeley PhD
|
|
2019–2021
On to: Common Sense Machines
|
|
Henry Stone
2018–2020
|
|
2018–2019
|
|
2017–2018
On to: Allen Institute for AI Residency; UW PhD
|
Extended Family PhDs
|
2022–2025
|
|
2021–2025
On to: Alibaba
|
|
2018–2021
On to: Synthesia
|
|
2014–2020
On to: Google
Publications:
|
|
2014–2019
On to: UMass Boston Faculty
|
|
2014–2017
On to: Reality Defender
|
Biography (2024)
James Tompkin is an Associate Professor of Computer Science at Brown University. His research at the intersection of computer vision, computer graphics, and human-computer interaction helps develop new visual computing tools and experiences from cameras. For this, his lab creates techniques for 3D scene reconstruction from multi-camera systems and for dynamics. His doctoral work at University College London on large-scale video processing and exploration techniques led to creative exhibition work in the Museum of the Moving Image in New York City. Postdoctoral work at Max-Planck-Institute for Informatics and Harvard University helped create new methods to edit content within images and videos. Recent research has developed new techniques for low-level reconstruction of dynamic scenes, view synthesis for VR, and AI content editing and generation.
Academic lineage
- Post-doc with Prof. Hanspeter Pfister at the Harvard Paulson School of Engineering and Applied Sciences.
- Post-doc with Prof. Christian Theobalt at the Max-Planck-Institute for Informatics and the Intel VCI.
- Research intern with Prof. Wojciech Matusik at Disney Research Cambridge.
- EngD VEIV student with Prof. Jan Kautz at University College London, sponsored by the BBC.
- MSci at King's College London with Ian Mackie.
Please find my research summary video from 2015—our newer lab work is on the 'Research' tab.
SIGGRAPH 50th—2023
I supported SIGGRAPH's 50th conference in 2023 as the chair of the Posters program, which was coincidentally running its 20th iteration too. Here's a meta-poster about the program's history and its outstanding contributors (low-res PNG).
{kind=link}
Faculty and Tenure Application Materials
To share my experience, here is the material I sent to Brown to apply for a tenure-track assistant professor position in Dec. 2015.CV (Sept. 2016)
Research Statement
Teaching Statement
Here is the material I used for my tenure case at Brown in Dec. 2023.
CV
Research Statement
Teaching Statement
Exhibitions
I supported the Discover program and club at Brown/RISD to pair arts and science students and put on an exhibition (2017–2021). I have also tried to contribute work myself.
Bad Art @ Brown, 2018
with Aaron Gokaslan and Vivek Ramanujan
{kind=link}
Rear Window Augmented
with Jeff Desom
Museum of the Moving Image
New York City
7th November 2015 to 10th April 2016
ISCP
New York City
7–9th November 2014
Festival Imaginales
Epinal, France
26–29th May 2014
Luxembourg Film Festival
28th February to 9th March 2014