← Back to homepage
Monocular Dynamic 3D Reconstruction
With only ordinary RGB video—no depth sensor, no rig—can we recover dynamic 3D scene geometry and motion?
Monocular dynamic 3D reconstruction takes a single moving camera observing a deforming scene and tries to recover a 4D representation including geometry, appearance, and motion. The problem is fundamentally under-constrained at any one instant, and progress depends on how well the chosen scene representation and supervision signals work together.
We've approached this in two ways. First, per-scene methods fit a representation to a single video. We consider what motion models and regularisations can help (GauFRe, MonoDyGauBench), and what additional information might resolve the ambiguity, e.g., semantics, attention, and optical flow supervision (SAFF). Second, Zero-MSF is data driven: a feed-forward model trained on millions of synthetic examples that transfers zero-shot to real video, with no per-scene fitting.
Authors
Abhishek Badki · Orazio Gallo · Leonidas J. Guibas · Adam Harley · Numair Khan · Eliot Laidlaw · Douglas Lanman · Yiqing Liang · Runfeng Li · Zhengqin Li · Alexander Meyerowitz · Thu Nguyen-Phuoc · Mikhail Okunev · Srinath Sridhar · Hang Su · Mikaela Angelina Uy · Lei Xiao
Papers in this thread
International Conference on Computer Vision (ICCV), 2023
Reconstructs a 4D neural volume carrying not just colour and density but also scene flow, semantics, and attention, then uses the latter two to decompose foreground objects from background across spacetime without supervision.
arXiv (Dec. 2023) + WACV, 2025
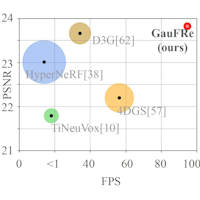
Casts monocular dynamic reconstruction as a canonical Gaussian template plus a forward-warping deformation field, with a separate static component initialised to absorb non-moving regions so the deformation focuses on what actually moves. Trains in roughly twenty minutes and renders in real time.
Transactions on Machine Learning Research (TMLR), 2025
An apples-to-apples benchmark of monocular dynamic Gaussian splatting methods, categorised by motion representation. Method differences are resolvable on synthetic data but get swamped by real-world scene complexity, and the optimisation is uniformly brittle.
Computer Vision and Pattern Recognition (CVPR), 2025
A feed-forward model that jointly predicts geometry and scene flow, trained on a one-million-sample synthetic recipe. Generalises zero-shot to casual DAVIS video and RoboTAP manipulation scenes—no per-scene optimisation required.