Controllable Generative Models
How do we efficiently control generative models to produce what we want—preserving identity, 3D structure, style—without sacrificing quality?
A generative model that can sample new content is impressive; one that produces exactly what a user has in mind is useful. Controlling generation requires aligning the model's latent structure with axes a person can articulate—identity, pose, style, lighting, geometry—without sacrificing the photorealism that brought the model to relevance in the first place. There is usually a quality-versus-control tradeoff to manage.
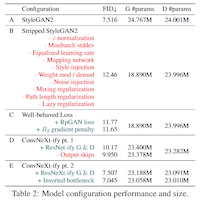
This thread runs from Youssef Mejjati's PhD work on unsupervised attention for image-to-image translation, through compositional controls (object stamps, GaussiGAN's 3D Gaussian primitives from silhouettes alone), into 3DMM-conditioned face generation where Yiwen Huang's PhD now sits. Two recent moves matter: TaxFreeGAN closes the FID gap to unconditional StyleGAN under 3DMM conditioning, and our disentangling-3D work shows that the noise in CLIP's embedding space—not the disentanglement strategy—is what kills quality. R3GAN sits alongside this arc as our architectural reset: a principled relativistic loss that lets the modern GAN drop its bag of tricks.
Authors
Akin Caliskan · Darren Cosker · Aaron Gokaslan · Yiwen Huang · Berkay Kicanaoglu · Hyeongwoo Kim · Kwang In Kim · Atsunobu Kotani · Volodymyr Kuleshov · Youssef A. Mejjati · Isa Milefchik · Christian Richardt · Zejiang Shen · Michael Snower · Stefanie Tellex · Vikas Thamizharasan · Oliver Wang · Yue Wang · Xinjie Yi · Zhiqiu Yu · Qian Zhang